Special Topics in Complexity Theory, Fall 2017. Instructor: Emanuele Viola
1 Lecture 18, Scribe: Giorgos Zirdelis
In this lecture we study lower bounds on data structures. First, we define the setting. We have 



- bit-probe which return one bit from the memory, and
- cell-probe in which the memory is divided into cells of
bits, and each probe returns one cell.
The queries can be adaptive or non-adaptive. In the adaptive case, the data structure probes locations which may depend on the answer to previous probes. For bit-probes it means that we answer a query with depth-
Finally, there are two types of data structure problems:
- The static case, in which we map the data to the memory arbitrarily and afterwards the memory remains unchanged.
- The dynamic case, in which we have update queries that change the memory and also run in bounded time.
In this lecture we focus on the non-adaptive, bit-probe, and static setting. Some trivial extremes for this setting are the following. Any problem (i.e., collection of queries) admits data structures with the following parameters:
and
, i.e. you write down all the answers, and
and
, i.e. you can always answer a query about the data if you read the entire data.
Next, we review the best current lower bound, a bound proved in the 80’s by Siegel [Sie04] and rediscovered later. We state and prove the lower bound in a different way. The lower bound is for the problem of 
Problem 1. The data is a seed of size 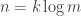


The question is: if we allow a little more space than seed length, can we compute such distributions fast?
Theorem 2. For the above problem with 
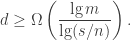
It follows, that if 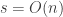


Proof. Let 

The intuition is that we will shrink the memory but still answer a lot of queries, and derive a contradiction because of the seed length required to sample
For the “shrinking” part we have the following. We expect to keep 
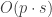

For the “answer a lot of queries” part, recall that each query probes 
We claim that with probability at least 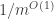



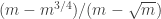
Thus, if 

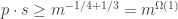

The minimum seed length to answer that many queries while maintaining 

from which the result follows. 
This lower bound holds even if the
We will now show a conceptually simple data structure which nearly matches the lower bound. Pick a random bipartite graph with ![S \subseteq [m]](https://s0.wp.com/latex.php?latex=S+%5Csubseteq+%5Bm%5D&bg=ffffff&fg=333333&s=0&c=20201002)




![\begin{aligned} & \Pr \left [ \exists S \subseteq [m], |S| \leq k, \textrm { s.t. } |\mathsf {neighborhood}(S)| \leq \frac {d |S|}{2} \right ] \\ & = \Pr \left [ \exists S \subseteq [m], |S| \leq k, \textrm { and } \exists T \subseteq [s], |T| \leq \frac {d|S|}{2} \textrm { s.t. all neighbors of S land in T} \right ] \\ & \leq \sum _{i=1}^k \binom {m}{i} \cdot \binom {s}{d \cdot i/2} \cdot \left (\frac {d \cdot i}{s}\right )^{d \cdot i} \\ & \leq \sum _{i=1}^k \left (\frac {e \cdot m}{i}\right )^i \cdot \left (\frac {e \cdot s} {d \cdot i/2}\right )^{d\cdot i/2} \cdot \left (\frac {d \cdot i}{s}\right )^{d \cdot i} \\ & = \sum _{i=1}^k \left (\frac {e \cdot m}{i}\right )^i \cdot \left (\frac {e \cdot d \cdot i/2}{s}\right )^{d \cdot i/2} \\ & = \sum _{i=1}^k \left [ \underbrace { \frac {e \cdot m}{i} \cdot \left (\frac {e \cdot d \cdot i/2}{s}\right )^{d/2} }_{C} \right ]^{i}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%26+%5CPr+%5Cleft+%5B+%5Cexists+S+%5Csubseteq+%5Bm%5D%2C+%7CS%7C+%5Cleq+k%2C+%5Ctextrm+%7B+s.t.+%7D+%7C%5Cmathsf+%7Bneighborhood%7D%28S%29%7C+%5Cleq+%5Cfrac+%7Bd+%7CS%7C%7D%7B2%7D+%5Cright+%5D+%5C%5C+%26+%3D+%5CPr+%5Cleft+%5B+%5Cexists+S+%5Csubseteq+%5Bm%5D%2C+%7CS%7C+%5Cleq+k%2C+%5Ctextrm+%7B+and+%7D+%5Cexists+T+%5Csubseteq+%5Bs%5D%2C+%7CT%7C+%5Cleq+%5Cfrac+%7Bd%7CS%7C%7D%7B2%7D+%5Ctextrm+%7B+s.t.+all+neighbors+of+S+land+in+T%7D+%5Cright+%5D+%5C%5C+%26+%5Cleq+%5Csum+_%7Bi%3D1%7D%5Ek+%5Cbinom+%7Bm%7D%7Bi%7D+%5Ccdot+%5Cbinom+%7Bs%7D%7Bd+%5Ccdot+i%2F2%7D+%5Ccdot+%5Cleft+%28%5Cfrac+%7Bd+%5Ccdot+i%7D%7Bs%7D%5Cright+%29%5E%7Bd+%5Ccdot+i%7D+%5C%5C+%26+%5Cleq+%5Csum+_%7Bi%3D1%7D%5Ek+%5Cleft+%28%5Cfrac+%7Be+%5Ccdot+m%7D%7Bi%7D%5Cright+%29%5Ei+%5Ccdot+%5Cleft+%28%5Cfrac+%7Be+%5Ccdot+s%7D+%7Bd+%5Ccdot+i%2F2%7D%5Cright+%29%5E%7Bd%5Ccdot+i%2F2%7D+%5Ccdot+%5Cleft+%28%5Cfrac+%7Bd+%5Ccdot+i%7D%7Bs%7D%5Cright+%29%5E%7Bd+%5Ccdot+i%7D+%5C%5C+%26+%3D+%5Csum+_%7Bi%3D1%7D%5Ek+%5Cleft+%28%5Cfrac+%7Be+%5Ccdot+m%7D%7Bi%7D%5Cright+%29%5Ei+%5Ccdot+%5Cleft+%28%5Cfrac+%7Be+%5Ccdot+d+%5Ccdot+i%2F2%7D%7Bs%7D%5Cright+%29%5E%7Bd+%5Ccdot+i%2F2%7D+%5C%5C+%26+%3D+%5Csum+_%7Bi%3D1%7D%5Ek+%5Cleft+%5B+%5Cunderbrace+%7B+%5Cfrac+%7Be+%5Ccdot+m%7D%7Bi%7D+%5Ccdot+%5Cleft+%28%5Cfrac+%7Be+%5Ccdot+d+%5Ccdot+i%2F2%7D%7Bs%7D%5Cright+%29%5E%7Bd%2F2%7D+%7D_%7BC%7D+%5Cright+%5D%5E%7Bi%7D.+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
It suffices to have 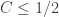

- if
for some constant
, then
suffices,
and
suffices.
Remark 3. It is enough if the memory is 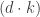

As remarked earlier the lower bound does not give anything when 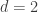
Problem 4. Take 

Theorem 5. You need 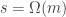
Proof. Every query is answered by looking at 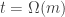

. Then you have a linear dependence, because the space of linear functions on
when we stop we have a query left such that both their probes query bits that have already been queried. This means that there exist two queries
and
whose probes cover the probes of a third query
. This in turn implies that the queries are not close to uniform. That is because there exist answers to
References
