
Save Newton MA
Update 15 2023: See new post. My understanding below was incorrect and should be ignored but I leave it here for historical record.
———————————————
A recent paper makes progress on two problems from my work on sampling permutations [Vio20]. First, it improves the cell-probe lower bound for sampling permtuations over ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002)
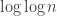

The present paper essentially shows you can have a flower with 
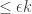

where 
By contrast, for smaller kernels you need

sets.
Given this, the improvement to sampling permutations is immediate using lemmas in my paper, and the communication viewpoint doesn’t seem to help that much: The goal is to show a lower bound on the number 

By Corollary 18 in [Vio20], the conditioning over a kernel of size 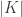


Now the setting is 



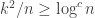


Looking back, it was rather dumb of me to not write down the above expressions, and realize that to get things going a flower with largish kernel sufficed. The way I stop thinking about these problems is what I call the 
A favorite open problem of mine in this area is: Can you sample a near-uniform permutation of
Out of frustration, in the paper I came up with a candidate distribution for a separation between adaptive and non-adaptive probes. I conjectured but I wasn’t able to prove a non-adaptive negative result (it’s easy to see that the candidate is samplable using 2 adaptive probes). This paper proves the conjecture! It’s not yet clear to me if the largish-kernel setting is essential for this or if a non-trivial separation follows from previous bounds (and I just missed it). Regardless, it’s great to see progress on these problems.
One of my obsessions over the years has been to somehow port the sunflower argument to the adaptive setting. The closest I think I got is the separator in [Vio23b], which basically shows that you can restrict the input to the sampler so that many queries are nearly independent. This can be used to prove some new sampling lower bounds which are also strong enough to imply succinct data-structure lower bounds. Alas, the parameters don’t seem strong enough for the permutation problem… or maybe they are, maybe I should think large kernels, extend the separator to that setting… one would also need to check if there is any useful generalization of Lemma 20 in [Vio20] I mentioned above to the setting of near independence, since in the adaptive setting we can’t guarantee complete independence…
[Vio20] Emanuele Viola. Sampling lower bounds: boolean average-case and permutations. SIAM J. on Computing, 49(1), 2020. Available at http://www.ccs.neu.edu/home/viola/.
[Vio23a] Emanuele Viola. Mathematics of the impossible: Computational complexity (working draft of a book). 2023.
[Vio23b] Emanuele Viola. New sampling lower bounds via the separator. In Conf. on Computational Complexity (CCC), 2023. Available at http://www.ccs.neu.edu/home/viola/.
