(This replaces an old post, where my understanding was wrong. I am grateful to the authors of [YZ24] for discussions which prompted me to look into this again.)
A recent paper, [YZ24], makes progress on two problems from my work on sampling permutations [Vio20]. First, it improves the cell-probe lower bound for sampling permutations over ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002)
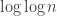

There are several ideas in their work, so it is not immediately clear where they gain from my work. They suggest that a key difference is what they call flowers, which is similar to sunflowers where the kernel just needs to be a little less than trivial, and then such objects start to appear even for smaller families.
Actually, this result was already known, and at times it was called “separator.” I quote a relevant lemma (similar statements appear in other works).
Lemma 1. (Lemma 2.3 in [Vio09]) [Separator] For every 



![w\in [n/(gq)^{q},n]](https://s0.wp.com/latex.php?latex=w%5Cin+%5Bn%2F%28gq%29%5E%7Bq%7D%2Cn%5D&bg=ffffff&fg=333333&s=0&c=20201002)




This appears to somewhat improve and simplify the proof of Theorem 2.1 in their paper.
The novelty in their work lies in the other arguments, which I find quite ingenious.
For the first type of results, I always needed that 

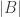


For the second result, they reduce sampling two equal sets with non-trivial error to the sampling of the candidate distribution. Then they prove a lower bound for the former (and for this they don’t need any decoupling). The argument is simple and, in my opinion, very cool.
Adaptivity
A favorite open problem of mine in this area is: Can you sample a near-uniform permutation of
References
[Vio09] Emanuele Viola. Cell-probe lower bounds for prefix sums, 2009. arXiv:0906.1370v1.
[Vio20] Emanuele Viola. Sampling lower bounds: boolean average-case and permutations. SIAM J. on Computing, 49(1), 2020. Available at http://www.ccs.neu.edu/home/viola/.
[Vio23] Emanuele Viola. New sampling lower bounds via the separator. In Conf. on Computational Complexity (CCC), 2023. Available at http://www.ccs.neu.edu/home/viola/.
[YZ24] Huacheng Yu and Wei Zhan. Sampling, flowers and communication. In ACM Innovations in Theoretical Computer Science conf. (ITCS), 2024.
